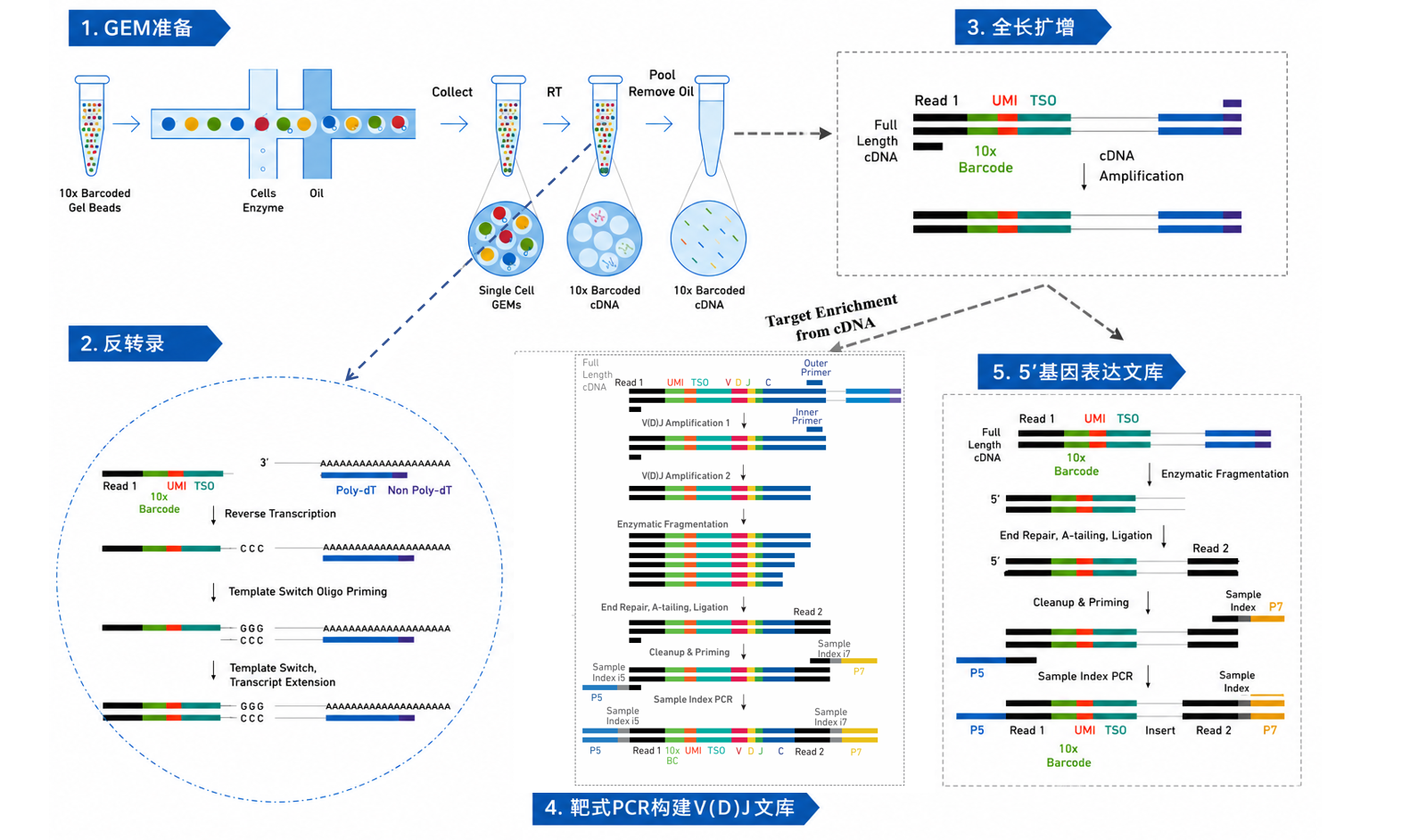
高通量单细胞转录组及V(D)J测序技术的核心在于捕获单个免疫细胞的转录组信息(5′ Gene Expression),并同步解析T细胞受体(TCR)和B细胞受体(BCR)的表达谱(V(D)J Enrichment),在单细胞层面实现基因表达与克隆型的联合分析。该技术可识别肿瘤浸润淋巴细胞(TIL)亚群、追踪抗原特异性克隆扩增、评估T/B细胞功能状态。
基于10x Genomics、BD、DNBC4等国内外多种单细胞测序捕获平台,提供从组织消化到结果分析的一站式单细胞测序解决方案。
专注于肿瘤临床科研领域,积累了丰富的肿瘤组织消化经验。除胃癌、肺癌、肠癌等常规易消化组织外,也通过技术优化,在胰腺癌、癌旁、血管、脂肪等疑难样本类型上形成经验优势。
单细胞转录组+V(D)J可同步获取,还可搭配单细胞蛋白质组,提供多组学联合分析服务,一次实验同时解析基因功能、克隆多样性及蛋白功能,助力科研成果加速转化。
T细胞和B细胞属于人体免疫细胞,在肿瘤免疫治疗、自身免疫性疾病以及移植耐受等方面发挥重要作用。每个T/B细胞都有自己独特的T细胞受体(TCR)或B细胞受体(BCR),如同细胞的“身份证”。
在适应性免疫中,T细胞可特异识别病原体携带的抗原,结合后迅速增殖,以精准、快速地杀灭病原体,这一过程称为细胞免疫;T细胞也能指导B细胞产生抗体,抗体与病原体表面的特异抗原结合后,引导其他免疫细胞清除病原体,这一过程称为体液免疫。两类免疫方式协同配合,共同保卫人体健康。
长期专注于临床科研领域,可将PBMC、全血、骨髓、血浆、石蜡切片(FFPE)、肿瘤组织等临床常见样品提取核酸后进行免疫组库测序。
每样本≥10M reads,可检测频率低至0.001%的稀有克隆;基于血浆样品的免疫组库测序满足液体活检级灵敏度。
支持TCRα/β/γ/δ及BCR的IgH/IgK/IgL各链测序,一次建库获取全谱系免疫图谱;还支持HLA基因分型,通过识别TCR序列与特定HLA等位基因的关联,推断TCR克隆可能针对的抗原。
支持免疫组库三代测序,采用独特的滚环扩增,扩增TCR和BCR的V-(D)-J序列全长(包括FR1-4和CDR1-3)。同一条TCR/BCR序列重复扩增后进行纳米孔测序,可大幅降低测序错误率。
自主生物信息学分析算法可进行V(D)J注释及克隆型定义,低错误率,结果可追溯、可复现,符合发表标准。可做标准分析和深度分析,也可联合其他组学进行整合分析。

转录调控组学(Transcriptional Regulation Omics)是系统研究基因转录全过程调控的多组学整合体系,核心解析“DNA→RNA”转录阶段的多层级分子机制,包括顺式元件、反式因子、表观修饰、染色质构象、非编码RNA等对基因时空特异性表达的协同调控网络。该体系以高通量测序为核心,从全局维度揭示细胞分化、发育及疾病状态下的基因表达调控规律。
宏基因组测序是以环境中全部微生物为研究对象,通过提取环境中整个微生物群落的总DNA,利用高通量测序技术进行大规模测序,并通过生物信息学分析研究微生物与环境、宿主之间的关系。该技术摆脱了传统研究中微生物分离培养的限制,具有通量高、准确性高、速度快、信息全等特点,能够显著加快宏基因组学研究进程,并在鉴定低丰度微生物群落及种类、挖掘更多基因资源方面具有优势。
该技术常用于研究环境微生物的群落结构、物种分类、系统进化、基因功能及代谢网络等,已广泛应用于微生物基因组研究。
直接提取微生物群落总DNA,无需分离培养。
可同时鉴定几乎所有微生物种类。
除物种信息挖掘外,还可获得群落表达的重要基因信息等。
可快速、高效、大样本地对微生物群落进行分析。
HLA(Human Leukocyte Antigen,人类白细胞抗原)是人类主要组织相容性复合体(Major Histocompatibility Complex, MHC)表达的产物,其编码分子参与抗原递呈,制约细胞间相互识别并诱导免疫应答。HLA位于人类6号染色体短臂约3.6Mb的免疫相关多态性区域,HLA复合体可分为经典HLA-I类(HLA-A、B、C)、经典HLA-II类(HLA-DP、DQ、DR)以及非经典HLA类。
HLA分子多样性非常高,存在大量等位基因变异,这种多态性保证了人类种群对各种病原体的广泛适应性和抵抗力。
通过分析TCR和HLA的结合模式,更好地理解T细胞如何识别特定抗原。
HLA基因具有高度多态性,不同个体可能对同一抗原产生不同反应;HLA测序可帮助了解个体免疫反应差异。
某些HLA等位基因参与甚至导致自身免疫性疾病、过敏性疾病、感染类疾病、代谢性疾病等复杂疾病的发生与发展,有助于识别疾病风险和开发个性化治疗。
理解TCR和HLA的相互作用,有助于设计能够激活特定T细胞反应的有效疫苗。
在器官移植和骨髓移植中,HLA-I类和II类分子是异体移植排斥反应中重要的免疫性抗原;通过HLA测序可提高供受者匹配和移植成功率。
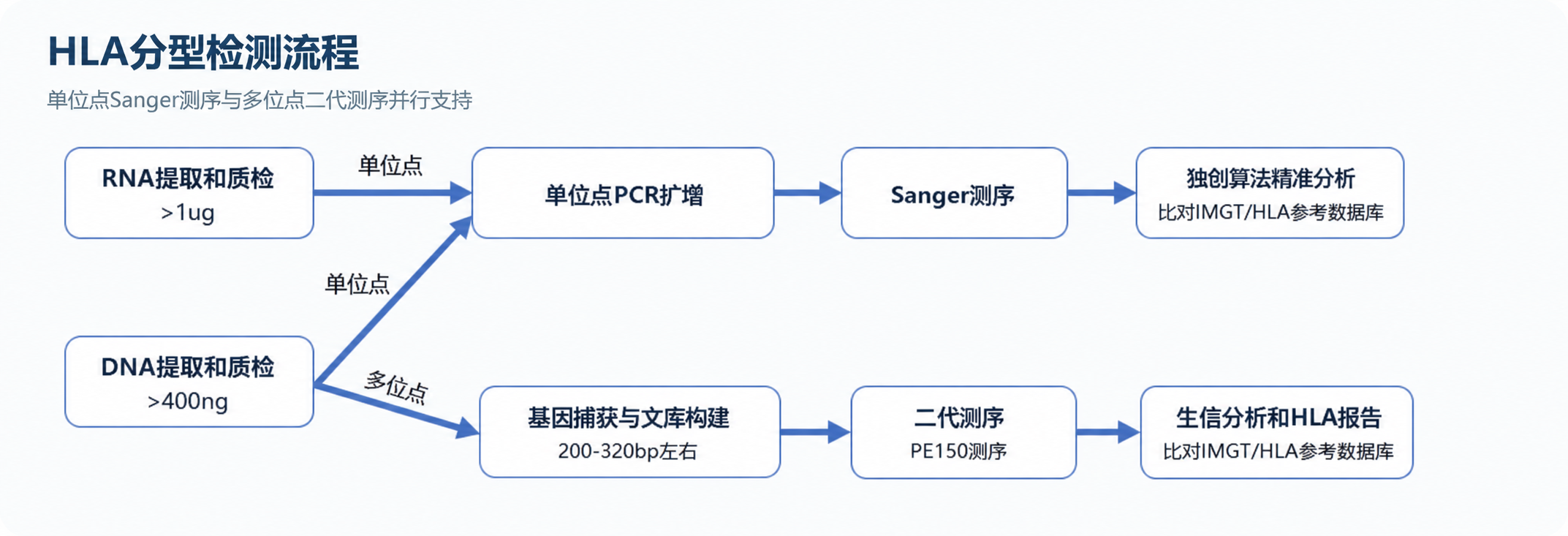


分型精度一般为4位,可高达8位。
NGS技术能够减少传统分型方法中可能出现的错误,提供更准确的HLA基因型数据。
覆盖HLA基因全长(含高变区),有助于识别未发现的等位基因。
可针对不同研究需求与样本类型定制。
DNA甲基化是经典的表观遗传修饰,主要发生在CpG二核苷酸位点,可调控基因转录、基因组印记、细胞分化、肿瘤发生与免疫稳态。CpG岛常富集于基因启动子区域,其甲基化状态与基因沉默或激活密切相关。
相较成本高、数据量大、周期较长的全基因组重亚硫酸盐测序(WGBS),简化代表性重亚硫酸盐测序(RRBS)通过MspI酶切(识别CCGG)富集CpG高密度功能区,如启动子、CpG岛和增强子,以更低成本高效覆盖关键调控区。
富集CpG高密度功能区域,靶向基因调控区,生物学意义更强。
测序数据量仅为WGBS的1/10~1/5,适合大样本队列批量检测。
精准定量甲基化水平,重复性好,技术稳定性高。
可同时分析启动子、CpG岛、基因体、重复序列等多区域甲基化特征。

告诉我们样本类型与研究目标,我们一起把方案定下来。
